
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于混合策略的中文生物医学领域未登录词识别研究*
引用本文
孙海霞, 李军莲, 吴英杰, 吴夙慧. 基于混合策略的中文生物医学领域未登录词识别研究*. 现代图书情报技术, 2013, 29(1): 15-21
Sun Haixia, Li Junlian, Wu Yingjie, Wu Suhui. The Study on Out-of-vocabulary Identification of Chinese Biomedical Field Based on Hybrid Method. New Technology of Library and Information Service, 2013, 29(1): 15-21
Permissions
Sun Haixia, Li Junlian, Wu Yingjie, Wu Suhui. The Study on Out-of-vocabulary Identification of Chinese Biomedical Field Based on Hybrid Method. New Technology of Library and Information Service, 2013, 29(1): 15-21
基于混合策略的中文生物医学领域未登录词识别研究*
摘要
简述中文未登录词识别研究现状, 结合中文生物医学领域词长分布和构词特点, 提出以N-gram为基础, 综合利用领域词典、语料和规则的中文生物医学领域未登录词识别方案, 并以中国生物医学文献数据库中药学期刊数据作为样本集进行实验, 效果表现良好。
关键词:
未登录词; N-gram; 混合策略; 生物医学
The Study on Out-of-vocabulary Identification of Chinese Biomedical Field Based on Hybrid Method
Abstract
First, the status of research on out-of-vocabulary automatic identification is introduced briefly. Then, combining the word length distribution and morphological characteristics of Chinese biomedical field, this paper presents an hybrid method of out-of-vocabulary identification of Chinese biomedical field, which is based on N-gram, integrating the methods of the field dictionary-based, filtered corpus-based, and rules-based. Finally, on a sample set of pharmaceutical journals data of Chinese BioMedical Literature Database, the authors make an experiment of the proposed hybrid method, and the experimental results achieve a good performance.
Keyword:
Out-of-vocabulary; N-gram; Hybrid method; Biomedical
1 引 言
未登录词的概念来自于中文信息处理领域, 目前还没有统一的定义[1]。本文中未登录词主要指当前所用词典中尚未出现的词, 它可能是一个旧词, 也可能是随着时代的发展而出现(或旧词新用)的词。未登录词是中文自动分词中遇到的难点和瓶颈, 其识别性能的优化能够有效提高分词精度, 促进中文信息处理的研究进展。
当前未登录词识别在通用领域已取得较好精度, 但在专业领域信息处理中还未取得较好的应用。本研究旨在提高中文生物医学关键词-主题词映射表(简称映射表)中关键词的文献覆盖率, 实现映射表与生物医学领域
文献增长速度的同步, 以及时揭示新兴研究成果, 满足中文生物医学文献自动标引、语义检索等需求, 因此, 在现有研究成果基础上, 结合生物医学领域构词特点, 进行中文生物医学领域未登录词自动化识别探索。
2 相关研究现状
就主要采用的技术看, 目前未登录词自动识别研究方法可分为三类:基于规则的方法、基于统计的方法和基于混合策略的方法[1]。
(1)基于规则的方法的基本思想是:根据新词的构词特征或外型特点建立规则库、专业词库或模式库, 通过规则匹配发现新词。如, 郑家恒等[2]以新词的构词知识为基础建立新词识别的常用构词库, 并且从网上词语的特征出发建立特殊构词规则库, 按照规则所起的作用分为“ 互斥性子串” 过滤规则、常规构词规则和特殊构词规则, 然后利用这些规则过滤并确定新词; 周雷[3]首先对分词结果中的碎片进行全切分生成临时词典, 然后利用规则和频度信息为临时词典中的字串赋权值, 最后利用贪心算法获得每个碎片的最长路径, 从而提取碎片中的未登录词。基于规则的方法一般来讲准确性比较高, 但需要人工以语言学为基础构造规则, 且多与领域相关, 可移植性较差[1]。
(2)基于统计的方法一般是首先利用统计策略提取出候选串, 然后或者利用语言知识排除不是新词语的垃圾串, 或者通过计算寻找相关度最大的字与字的组合。常用的统计模型有支持向量机模型(SVM)、t测试原理、n元语法(N-gram)、隐马尔科夫模型(HMM)、条件随机场模型、神经网络模型、最大熵模型等。如, 段宇锋等[4]以植物学期刊论文为专业领域样本, 开展了基于N-gram的专业领域中文新词识别研究; 韩艳等[5]通过左右邻信息获取二元候选未登录词种子, 然后在二元候选未登录词种子基础上不断扩展, 识别出不限长度的新词; 李钝等[6]利用单字之间的共现词频信息以及出现的时间规律确定候选未登录字串, 然后利用候选未登录字串中各字符相邻、有序、频繁出现的特点, 采用相关的挖掘算法进行未登录词识别。
(3)基于混合策略的方法主要是将上述两类方法结合。基本思路是:先利用基于统计的方法得到候选字符串, 再利用基于规则的方法剔除垃圾串, 符合规则的候选字符串即作为识别出的新词。如Wu等[7]对文本进行分词和人名识别, 分别计算剩余字串中单个汉字和多个汉字构成独立词的概率, 并设定阈值挑选新词候选字串, 再根据候选字串的词性、位置与词长之间的关系, 计算候选字串可能成为一个独立词的概率, 并根据阈值判断候选字串是否是新词; 曹艳等[8]利用N-gram获取候选字串, 然后利用过滤规则进行垃圾串过滤。
3 基于混合策略的中文生物医学领域未登录词识别研究方案
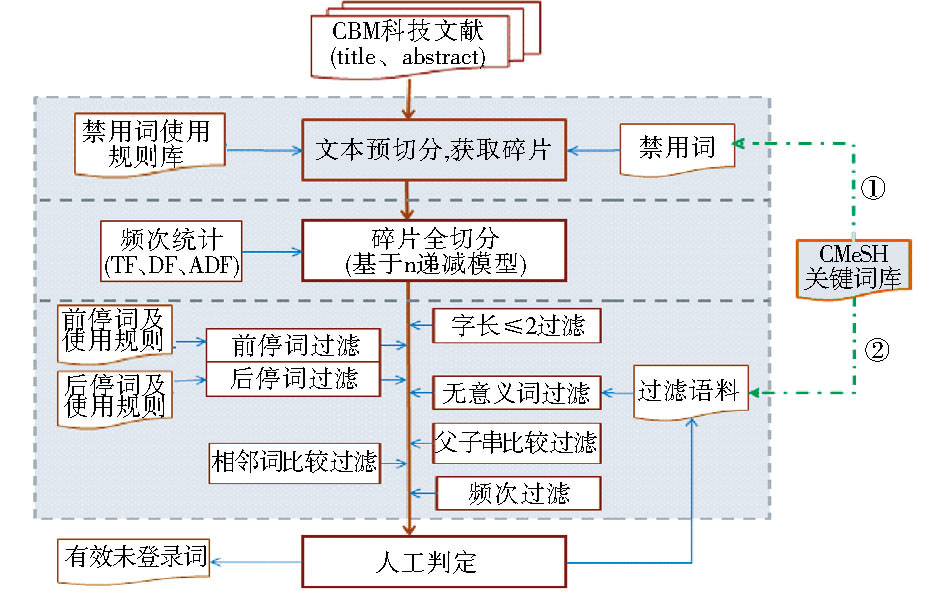
3.1 技术方案设计
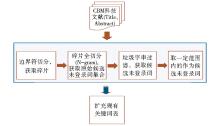
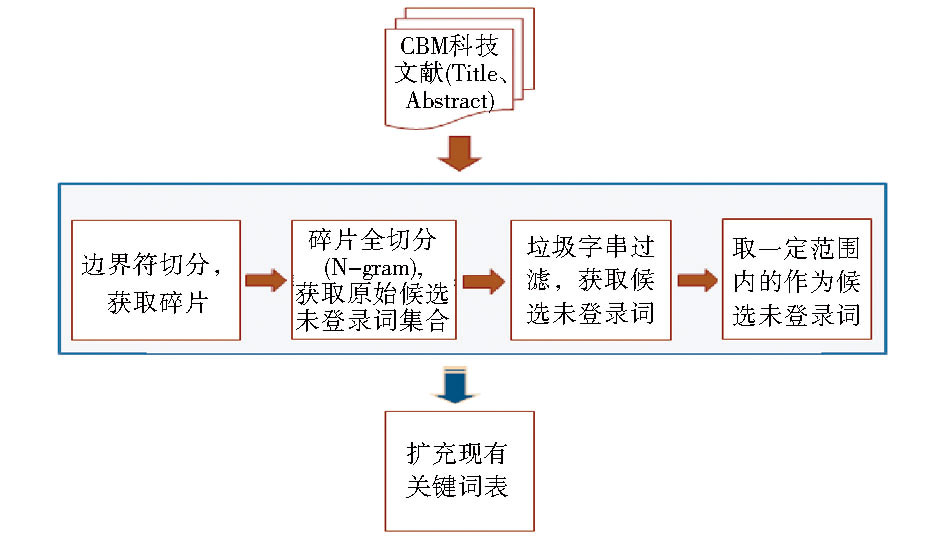 | 图1 基于中文生物医学期刊数据的领域 |
未登录词识别技术方案
如图1所示, 整个方案以较为成熟的N-gram统计法为基础, 综合考虑基于词典和基于规则的方法。主要包括4个步骤:
(1)有效碎片获取:利用边界词表对文本进行切分, 获取可能包含未登录词的碎片;
(2)碎片全切分:采用N-gram统计法, 基于n递减模型扫描有效碎片提取候选字串;
(3)候选未登录词获取:采用系列后处理规则从候选字串中对“ 垃圾字串” 进行过滤, 获取优选未登录词;
(4)未登录词识别:选取一定频次范围的候选未登录词作为正式未登录词。
方案预设三个频次函数, 即词频(Term Frequency, TF)、文档频率(Document Frequency, DF)和平均文档频(Average Document Frequency, ADF), 以了解哪种频次计算函数最适合作为本方案的有效未登录词过滤函数。
具体规则详述如下:
(1)N-gram算法应用设计
N-gram算法因具有与语种无关、不需要语言学处理基础、不需要词典和规则、不需要训练语料等优点, 常被用来开展分词和未登录词识别研究, 基本思想如下:将文本按长为N的窗口进行滑动, 形成长度为N的字符串, 一个字符串称为一个gram; 统计所有gram出现的频次, 并按照事先设定的阈值进行过滤, 获取有效字符串作为分词或未登录词结果。其中, 最小滑动文本单位和滑动窗口大小的选择直接影响最后结果。本研究方案中:
①关于最小滑动文本单位界定:根据最小滑动文本单位的取值不同, 现有基于N-gram的未登录词识别方法可分为基于单字符的方法和基于词的方法。贺敏等[9]证明基于词的N-gram识别效率较高, 但张海军等[10]证明基于字符的N-gram方法能够获得较好的召回率, 基于词的N-gram方法能够获得较好的准确率, 且随着样本容量的增大, 两者的差别是先增大后减少, 当样本容量极大时, 差距很小, 但这种容量很难达到。本研究的基点是, 在两者差距不是很大的情况下, 更侧重于未登录词的召回率, 因此, 采用基于字符的N-gram识别方法, 结合生物医学领域新词中化学名称、分子式等占有较大比例这一特点, 为避免完全由非中文字符组成的新词被破坏, 规定连续的非中文字串等同于一个汉字字符, 如“ CO2化学作用” 的3-gram切分的结果为“ CO2化学/化学作/学作用” 。
②关于滑动窗口大小的选择:采用n元递减模型, 即分别采用n, n-1, n-2, … , 2, 1作为滑动窗口文本长度获取原始字串。
(2)后处理规则
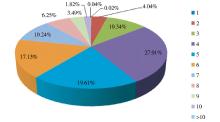
①基于字长的过滤规则:在通用领域中, 二字词的未登录词占有很大比例, 但在生物医学领域并非如此, 以中国医学科学院医学信息研究所构建的中文生物医学关键词语料为例, 二字词所占比例仅为4.04%, 且其中近50%为文献类型词或地区特征词。此外, 领域新词主要为复合词和衍生词, 因此, 切分结果中单字长和二字长的纯中文字串直接被过滤。
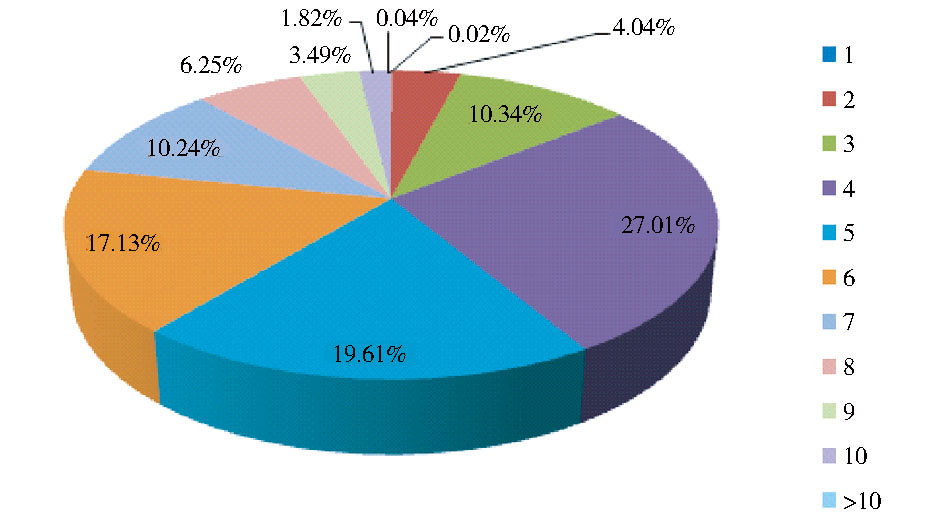 | 图2 中文生物医学关键词语料字长分布统计 |
②基于前停用词和后停用词的过滤规则:总结领域关键词库中一般只出现词尾(或词头)但很少出现在词头(或词尾)的词, 构建前停用词典、后停用词典以及相应的特例词典, 用以过滤切分结果中以前停用词开头(或以后停用词结尾), 且不在特例词典中出现的字串。
③基于子串和父串比较的过滤规则:设子串由父串中若干个连续字符组成。曹艳等[8]在研究中以子串I为中心, 通过比较子串I和所有文献中父串的长度差和频率差来决定子串和父串的取舍。本文认为:
1)在主题标引和信息检索中, 长度较长的词一般更能表达特定主题概念;
2)生物医学领域新词集中体现为复合词和衍生词;
3)如果子串能够作为一个独立新词出现, 在文本集合较大情况下, 一定能够在不依附父串的情况下独立出现。
因此采用如下过滤方案:
1)子串和父串F的关系限制在同一篇文献内有效;
2)以父串F为判定中心;
3)不考虑串长差距和频度差的变化情况, 如果子串和父串F的频次相同则直接过滤子串, 保留父串。
④基于相邻词比较的过滤规则:同时满足如下两个条件的字串认为是相邻字串:字串A和字串B的长度相同; 只有字串A首字和字串B的尾字不相同, 其他字都相同。对此, 单篇文献内, 如果A和B的频次相同, 则同时过滤; 如果频次不同, 则取高频者。
⑤基于过滤语料的过滤:直接将结果中出现在过滤预料中的词过滤。过滤语料中包含收录每轮实验后经人工判定确认为无意义的字串。
(3)现有领域关键词库介入阶段的思考
不同研究者关于现有词典在未登录词识别中的介入阶段并不一致。如魏莎莎[11]在切分过程中引入现有词典, 即除了采用停用词作为切分标记, 现有词典中的词条也作为切分标记的一部分; 曹艳等[8]在候选未登录词过滤阶段引入现有词典, 作为切分结果非候选字串过滤的依据。前者的不足是可能将字长较长的未登录词串破坏; 后者虽可以避免上述情况出现, 但后续垃圾字串过滤压力较大。为寻求适合本领域的介入阶段, 在具体实验时采用两种方案, 以作对比。
3.2 实验方案设计
(1)实验目标.
①比较在不同阶段引入现有关键词库的效果;
②上述条件下, 分析本文提出的未登录词识别方案整体效果;
③在相同过滤规则下, 比较不同频次过滤函数下的未登录词的识别效果;
④比较不同字长未登录词识别效果。
(2)测试文本选择.
以中国生物医学文献数据库(CBM)[12]中2011年和2012年上半年的《药学学报》中所有期刊论文的题名和摘要作为测试数据源。原因如下:
①选择药学, 主要考虑药学发展较快, 经常有新词(如药品化学名称、药品商标等)出现, 且其构词方式和通用词汇不同, 能够有效代表专业领域的特殊性, 较好反映专业语境对未登录词识别策略带来的影响。《药学学报》作为药学领域最具影响力的学术期刊之一, 能够反映和覆盖药学领域的最新研究进展和成果。
②选择CBM, 是因其作为国内生物医学领域权威的数据库之一, 收录了国内相关领域98%的期刊的论文, 而《药学学报》作为领域内的核心期刊则全部被收录; 另外, 也是因为它是本研究的最终服务对象和应用环境。
③选择期刊论文, 是因为期刊论文连续性强, 用户覆盖广, 内容比较可靠, 格式和用词比较规范, 常被学术界视为权威的知识来源, 因此从中提取的未登录词具有专业性、可靠性和稳定性。
④选择期刊论文的题名和摘要, 而不是全文, 主要是考虑N-gram切分自身时间复杂度较高, 全文切分工作量太大, 且文献[8]表明, 从标题和摘要中识别未登录词能够取得较好的效果。
(3)实验步骤
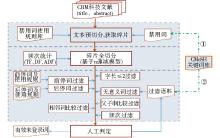
根据上述研究思路、技术方案和研究目标设计的中文生物医学领域未登录词识别流程如图3所示:
 | 图3 中文生物医学领域未登录词识别实现流程 |
①将数据分为两个测试集:2011年数据集, 共128篇文献; 2012上半年数据集, 共59篇文献。原因是:初始测试时, 过滤语料为空, 但随着实验次数的增加和过滤语料的累加, 认为识别结果的准确率会有提升。
②关于禁用词和规则库:禁用词的来源包括哈尔滨工业大学的中文通用禁用词表[13]、中国医学科学院医学信息研究所的中文医学主题词禁用词表中国医学科学院医学信息研究所.中文医学主题词禁用词表[K].2002以及在数据处理过程反馈获得词条。规则库中规定了哪些特例情况下禁用词表中的词条不能作为切分标识。如“ 的” 一般都作为禁用词, 但是在处理生物医学文本时, 出现“ 氢化可的松” 等这样的特例词条, “ 的” 则不能作为文本的切分标识而将文本“ 氢化可的松” 切分为“ 氢化可” 和“ 松” 。
③关于n取值, 考虑实验效果, 未取最长值, 而是结合碎片长度分布统计结果(2<n≤ 7的碎片占所有碎片的97%以上)和现有关键词语料中词长统计结果, 取值为7。
4 实验结果分析
与人工识别结果进行对比分析, 并引入准确率P、召回率R和F值三个指标。

4.1 既有关键词语料介入阶段对比分析
如表1所示, 就准确率而言, 方案1稍优于方案2; 但就召回率和F值看, 方案2远优于方案1。
(注:时间较长的主要原因是TF、DF和ADF的统计是在N-gram全切分中完成。)
设将既有关键词语料作为切分词典介入作为方案1, 将既有关键词语料作为候选未登录词过滤语料介入作为方案2, 主要从以下三个角度对比两个方案的效果:正确识别的未登录词总量和相互交叉情况; 准确率、召回率和F值; 时间消耗。需要说明的是, 以下分析结果是在初次过滤语料为空的情况下进行, 即基于2011年测试集的实验结果进行分析。
(1)识别总量和交叉情况分析
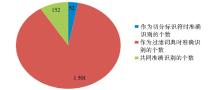
方案1共获得1 000个N-gram, 经过人工对比审核, 共获得有效未登录词204个; 方案2共获得8 725个N-gram, 经过人工对比审核, 共获得有效未登录词1 653个。其中, 两种方案共同准确识别152个, 即方案1准确识别出来的未登录词中有74.51%的为方案2所包含, 如图4所示。
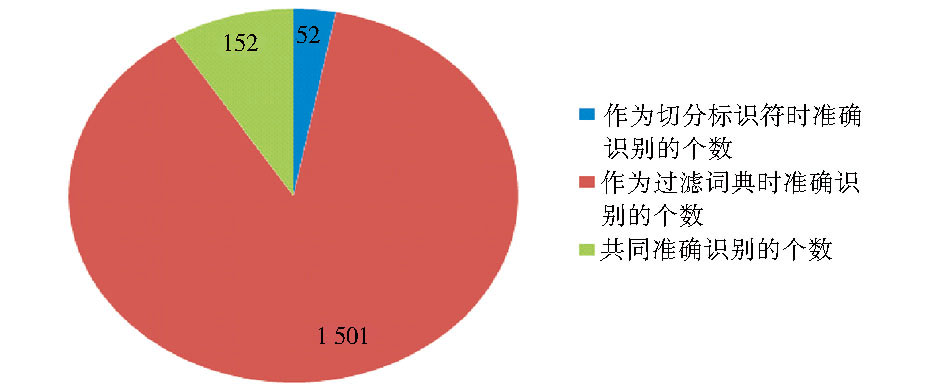 | 图4 不同介入阶段准确识别结果比较 |
(2)准确率、召回率和F值对比分析
| 表1 不同介入阶段的P、R、F值对比分析 |
(3)时间消耗对比分析
在不同实验阶段, 两种方案的时间消耗统计情况如表2所示, 可以看出, 方案2优于方案1。
| 表2 时间消耗对比分析 (分钟) |
(4)小 结.
综上所述, 笔者初步决定将现有关键词表作为过滤词典介入到未登录词识别过程。未来将在过滤语料不为空的情况下对准确率P、召回率R、F值和时间消耗进行分析。
4.2 方案整体效果分析
(1)就准确率P、召回率R和F值来看, 方案2的实验效果优于文献[8]和文献[11], 逊于文献[4]和文献[5], 但整体表现效果良好。
(2)过滤语料基础的好坏直接影响整个方案的效果, 虽然只是经历了两轮实验, 但效果已经非常明显。随着过滤语料的积累和完善, 实验效果会更好。
采用方案2进行如下分析, 其中基于2011年测试集进行实验产生的过滤语料应用在2012上半年测试集实验中。实验结果分析情况如表3和表4所示:
| 表3 不同测试集和过滤语料的实验结果分析(1) |
| 表4 不同测试集和过滤语料的实验结果分析(2) |
4.3 不同频次过滤函数效果分析
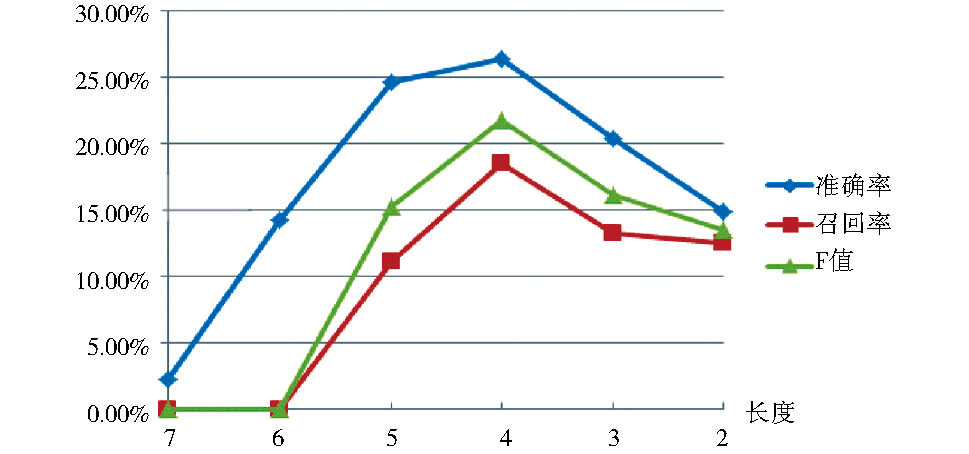
(1)对于正确识别出来的未登录词覆盖率, 当达到一定阈值范围时, 不同过滤函数之间的差异不大, 如图5所示:
在准确率P、召回率R、F值三个指标基础上, 笔者引入覆盖率C评价指标, 即不同阈值范围内, 当前过滤函数正确识别的未登录词数占所有过滤函数正确识别出来的未登录词数的比例。设过滤函数Yi正确识别的未登录词集合为Ai, 所有过滤函数正确识别的未登录词集合为A, 则:

| 表5 不同TF阈值范围的评估结果 |
| 表6 不同DF阈值范围的评估结果 |
| 表7 不同ADF阈值范围的评估结果 |
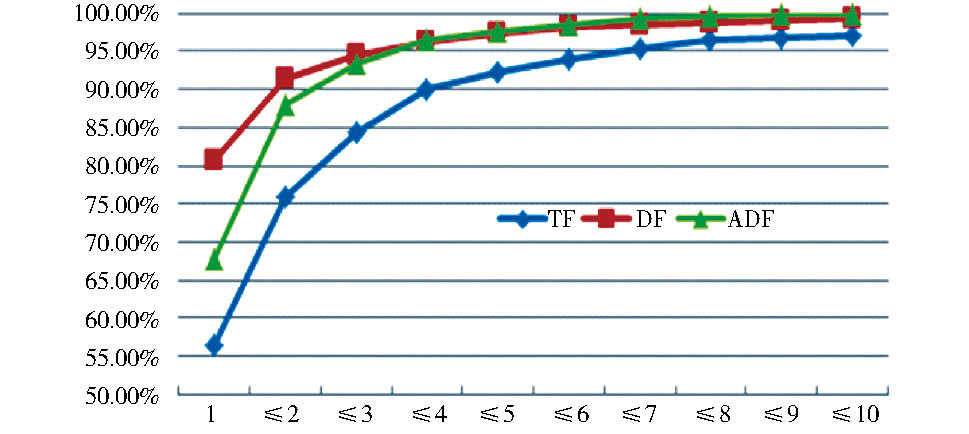 | 图5 不同过滤函数相同阈值范围下的 |
覆盖率对比分析
(2)对于频次过滤函数的选择, 在正确识别出来的未登录词覆盖率基础上再综合考虑准确率P、召回率R和F值, 词频TF表现最差, 平均文档频ADF表现稍优于文档频率DF。
5 结 语
本文在现有未登录词识别技术基础上, 结合中文医学领域词语长度分布特点和构词特点, 以药学作为专业领域样本, 开展医学领域的未登录词自动识别探索, 并以中国生物医学文献数据库中2011年和2012年上半年的期刊数据作为样本集进行实验验证, 效果良好。未来将进一步从如下角度开展研究:
(1)确定不同后处理规则的最优组合顺序。当前实验并没有将重心置于后处理规则的组合优化方面, 但从上述规则可以看出, 不同的组合方案对准确率、召回率和时间消耗都有影响, 尤其是对时间消耗的影响较大。
(2)优化 “ 基于子串和父串比较的过滤规则” 和“ 基于相邻词比较的过滤规则” , 并在实验和实践中优化频次过滤函数及其阈值范围的选择。
(3)持续构建过滤词典, 用以存放每次实验数据经切分过滤, 再由人工判别后过滤掉的无意义字串, 作为后续实验和应用处理的“ 垃圾字串” 的过滤字典。
(4)进一步细化字长过滤规则, 主要是单字长的纯英文字串和二字长的中英文混合字串, 这是由中文生物医学领域的构词特点决定的。
(5)将当前方案应用在其他医学子领域进行分析验证和优化。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|